2023年の雑感
今年の振り返り
相変わらず記事の投稿は継続できていませんでしたが、2023年について振り返ろうと思います。
今年もあと数日で終わってしまいます。年々早くなっているように感じます。
変わったこと
今年の春に入籍しました。
仕事
特段何か新しいことをやった訳でもなく、今年もレガシーコードを書き換えたり、機能追加したり、依存関係を整理したりしていました。 チームメンバの人数が増えたこともあり、業務としては昨年よりもピープルマネジメントの比重が増えました。 なので、主に雑用をやる人になってます。
他には部署横断プロジェクトのリードをやったりしてました。 プロジェクトでは、顧客からのエスカレーションを開発側に通達する業務フローの運用改善をしてました。 普段と違った仕事に携わるのは新鮮でした、円滑に進んだのが何よりでした。
あんまり書くことなかったので、趣味について書こうと思います。
趣味
ポーカー (2023.01 - 2023.06)
ポーカー (NLH) にハマりすぎて、ポーカーの勉強・研究をしていました。
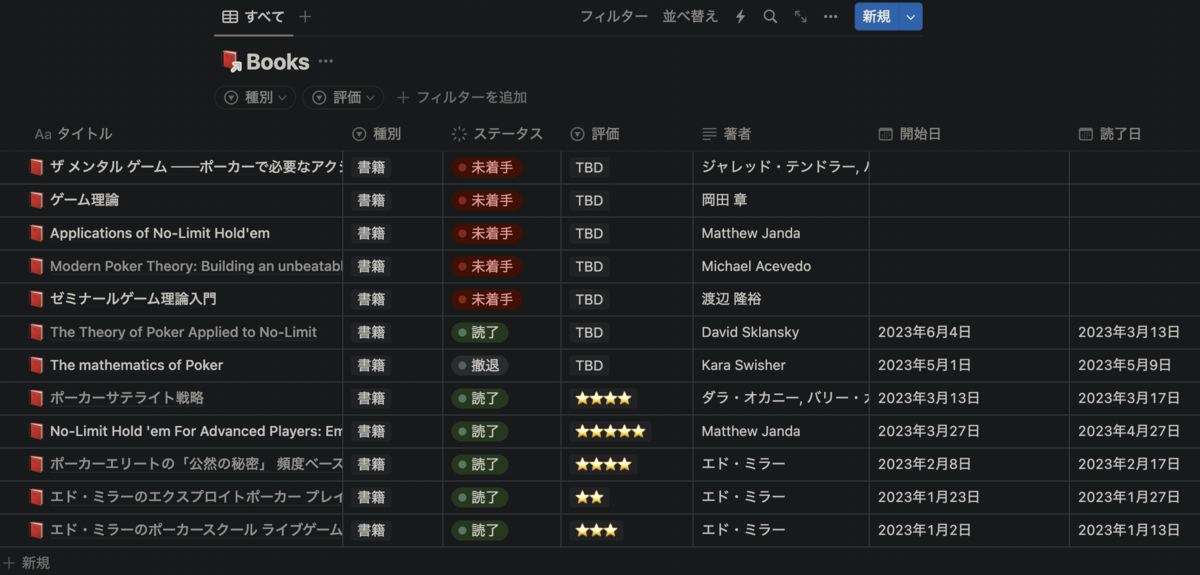
読んだ・読もうとしてた書籍↓
最初はGTO Wizardを使っていたのですが、当時自分の簡易レンジ vs 任意レンジでの解を得る機能がありませんでした。 途中からはソルバーのGTO+を使って難しいスポットの勉強をしたり、レンジの構築を研究してました。
JOPTという日本のポーカーの大会があるのですが、そのトーナメントの一つで運良く結果を残すことができました。

本当に運が良かっただけで、実力はまだまだ50nl以上を打つ人には敵わないです。
秋にはラスベガス/バルセロナでキャッシュゲームを経験することが出来ました。 資金もそんなに無いので、$1-3/€1-3を打っていました。 ベガスでは頻繁にストラドルが入るので、実質的には$2-5になっていました。時間帯にもよると思うのですが、自分が稼働していた時間はそれ以上の卓が殆ど立っていなかったのも覚えています。
熱が完全に冷めたわけではないのですが、現状もう一方の趣味に時間を使っているため、最近は会社のポーカー部で遊ぶ程度になりました。勉強する時間も無くなりました。
来年機会があればMIXゲームを始めたいです! オマハの本も途中まで読んでる最中だったので、一先ずそれを読み切って基礎を身につけるところからですね。
競馬AI (2023.07 - )
春競馬が終わった段階で、競馬AIの開発にまた戻ってきました。 自分の性格上、一度辞めた趣味に何度も戻ってくることは珍しいです。StarCraft 2以外でそんな状況になったことはないです。
特徴量の数を増やしたり、バグを直したり、リークを直したり、モデルの作成方法を変えたり、等などモデルのバージョンもv5 -> v6 -> ... -> v7_7 と継続して更新し続けています。
また、秋から冬にかけては、競馬AIコンペに出場しました。 ここで他の開発者と競い合うことがモチベになりました。上位陣のAIにはまだまだ敵いませんでしたが、大変刺激になりました! tikeda-meu.hatenablog.com
未だに改善は続けています、安定した成績まであともうちょっとという感じです。 モデルの適正な評価が難しいと常々感じています。
robustな妙味を永遠に探してます。
出張・旅行
今年は色んな場所へ行きました。
国内だと、鹿児島・福井・広島・大阪に訪れました。 国外だと、アメリカ(ラスベガス)、スペイン(バルセロナ・マドリード)に訪れました。
あと大西洋を横断したら、地球一周できてました。
スペインは特に良かったです。食事◎景色◎値段◎でした。
マドリード良き pic.twitter.com/KASXI8x2rE
— めう🐟🐾 (@motacapla) 2023年10月8日
アメリカは物価が高すぎて、日本から持ち込んだカップ麺を主食にしてました。 シーザーズパレスのバフェが有名で、そこで豪華なランチを食べてきました。
シーザーズパレスのバフェにきた!
— めう🐟🐾 (@motacapla) 2023年9月21日
コンプで少し安くなりました pic.twitter.com/6XbVD4Pdzg
それにしても、チップスはあんなに安いのにクッキーは高いの何でなんだろう
クッキーが軒並み$5ほどすることに驚きを隠せない
— めう🐟🐾 (@motacapla) 2023年9月18日
水10本買えるじゃん
めちゃくちゃ韓国行きたいです。日本以外のアジアの国行ったこと無いので、次はきっと韓国です。
今年はそんな感じです、来年はさらなる飛躍の年にしたいです。 また来年もよろしくお願いします。
AI競馬予想マスターズ2023に参加しました
netkeiba主催のAI競馬予想マスターズ2023という大会に参加しました! yoso.sp.netkeiba.com
競馬AIを作っている人々が集まって、競い合う大会です。 予選1, 2を通過した参加者が集められ、各予選で稼いだ金額を元手に本戦で競い合うというルールでした。 詳しいルールは以下のページに記載されています。 AI競馬予想マスターズ2023 | 大会ルール | netkeiba.com
予選では運がよく、本戦には4位で出場できました。が、本戦では結果を残せず終いでした。 残念な結果に終わってしまいましたが、得られたものは大きかったと自分は思っています!
↓ハナ差で本戦3位を逃す(負け惜しみ)
阪神カップのハナ差、幻の3着は惜しかったhttps://t.co/W0J7PfQNFq
— めう🐟🐾 (@motacapla) 2023年12月24日
他の参加者の買い目を見て自分の学習モデルでは購入できない馬券があることを知り、これがきっかけとなって計算式に間違いを見つけました。 モデルの特徴量を増やしたり、リークを直したりと、開催期間中はモデルの精度改善に尽力していました。ここまで精力的に活動するのは、こういったコンペという形式で急かされなければ難しかったと思います。ソロ開発なら尚更です。
また、以前からドメイン知識も十分でないと感じていたので、大会期間中の空き時間で本を数冊買って読んだりしました。
本やネットで情報を集めている中で、異なるアプローチでのモデル/買い目構築を思いつきました。 早速新しいモデルの作成まで進めていて、現在は実戦経験を積んでいる最中です。 (せっかくであれば本戦でも試せればと思いましたが、間に合いませんでした。)
シミュレーション上は良いパフォーマンスを見せてくれているのですが、確定後オッズしか利用できていないので、実戦では若干の乖離があると予想しています。そしてリークや過学習してないかが怖い。

数年単位で確認して設計していて、そこそこ堅牢な特徴量を予想の材料に使ってくれているはずです。 新モデルがうまく行って、気が向いたら別記事を書こうかなと思います。
こんな素敵なコンペを開催してくださったnetkeibaの運営の方々に感謝です。 また来年以降も開催されれば、ぜひ参加します!
競馬における期待値 (EV) と資産 (BR) あたりの掛け金の考察
投資において、資産 (BR) の何%をリスクに掛けるかは非常に重要な問題である。 この割合を間違えると破産しかねるし、逆に複利をうまく活かしきれないことにもなりかねない。 どちらも損失である。
競馬の馬券購入にも同じ考えが当てはまる。今回は単勝と複勝の簡単な実験を行った。
両馬券の的中に関して完全に独立事象とし、それぞれの的中率は単勝15%、複勝30%とした。
def hit(th):
return random.random() < th
def try_tansyo():
return hit(0.15)
def try_fukusyo():
return hit(0.30)
1レースあたり、半ケリー基準で配分した数量でそれぞれ単勝と複勝を購入する。 当たったときにはそれぞれ単勝は10倍、複勝は5倍の払い戻しとする。
まずは単勝のみ購入し続けた場合、

続いて複勝のみ購入し続けた場合、

と、それぞれ期待値通りの右肩上がりのグラフになる。
一方で単複の両方を購入し続けた場合、

意外な結果に驚くかもしれないが、右肩上がりにならない世界が生まれる。 半ケリー基準で両馬券を毎レース購入すると、BRが金額に耐えられず伸びない。 実は、半ケリー基準ですら全然安全ではない。
試しに 1/4ケリー基準で購入金額を落としてシミュレーションしてみると、

今回の実験から、多くの種類の券種を購入する場合には金額配分に気をつけましょうという結論です。
2022年の雑感
今年の振り返り
今年も特にブログを書いてなかったので、1年越しの投稿となりました。皆様、いかがお過ごしでしょうか。 去年と比べ、働く環境が変わったり趣味が増えたりと激動の1年だったように思います。
仕事
4月から現職のサイボウズでWebエンジニアとしてkintoneの開発に携わっています。 前職だとフロントエンドのソースコードを触ることは無かったのですが、現職からはバックエンド(Java)・フロントエンド(Closure Library, React.js)両方とも触ってるような状況になりました。
基本的にはチームでモブプロをして活動していて、機能開発や改善、性能検証、調査などの業務をこなしています。 チーム活動外にも改善系プロジェクトがいくつも立っており、そういった活動に参加することも可能です。 自分も二つの改善系プロジェクトに参画していて、その内の一つにはかなり力を入れて開発していました。 他にやっていたこととして、メンター業や採用活動にも可能な限り協力していました。
環境が変わった時に頑張らなければいけないことの一つに、そのプロダクトのソースコード・ドメイン知識のキャッチアップがあると思います。 チームでの活動がモブプロが主体になっていること、ドキュメントや教材が充実しているところもあり、オンボーディングの環境がかなり整っていると感じました。
秋頃から機能単位で切ったフューチャーチームで開発する体制に切り替わり、新しいチームでの活動も始まりました。 現体制がいつまで続くかはまだ分からないですが、来年以降もまずは業務をこなせるようなチームにしていければと思っています。
趣味
エッジを追い駆ける - OASOBI
釣り
GWや秋に離島・五島列島への釣り旅行を計画していましたが、台風直撃でキャンセルになって行けずじまいでした。 コルトスナイパーの5本継ぎモデル欲しいな〜って思っていたら、コルトスナイパー XR MB S100MH-5 がマジで出たので即買いました。 まだ入魂できてないので、来年はヒラマサを釣りたいです。あと、今年の秋もカワハギ釣りに行きました。
競馬
一口馬主の方は、なんと出資したグランベルナデットちゃんが1勝上げてくれました! db.netkeiba.com 新馬戦後、手術と療養期間があってそこからの復帰戦でしたが、かなり強い勝ち方で後続をぶっちぎったので来年以降も楽しみです。 クラシックも視野に入れていて、オークス、桜花賞あたり賞金を加算したら出ようと思っているというコメントがあって、出走が叶ったら応援しに行きたいです。
馬券の方は、今年初めてエッジを見つけ、消失し、新たなエッジを探すことに没頭した一年でした。

某有名AIが予想公開を取りやめたことで、せっかくなので自作した競馬AIモデル(https://twitter.com/meumeu_ai)を使ったシミュレーションから実践投入まで取り組んでいました。趣味の中ではこれに一番力を入れていたと思います。 自分のモデルは厳密には1着確率を求めているものではないので、1着確率をより正しく求められるモデルを作りたいなと思ってます。 (現行モデルの成績もどこかでまとめようと思います。) 来年以降も中央競馬の精度も向上させたいですし、地方競馬対応も行いたいです。一人でやっていてもモチベ保てないので、一緒にモデル作ってくれる仲間探してます。
買い目の話でいうと、5分前オッズ (更には30秒前オッズまでも) が確定オッズとかなり乖離があることが分かり、そのギャップにかなり悩まされています。 Mambaの記事でも同様の現象が観測されていて、7.3%程落ち込むようでした。勿論この数値は券種やレース番号によっても差が出てくると思います。 dmv.nico 買い目を作る方法として、各買い目のエッジ (=確率*オッズ) を算出して期待値が閾値を超えたものを買うやり方がありますが、未確定オッズ情報から確定オッズが推定できないと、運用するのは難しいです。 他の方々がどう構築しているか是非お聞きしたいですが、可能なら買い目自体は確定前に得られる情報だけで構築できると良いと思っていて、あまりオッズや人気には依存させたくないです。
トレード
適当な銘柄のEDAをしたり、
信用取引口座を開設して、トレードの自動化を試みたりしました。 au株コム証券だと発注用のAPIがあるのでそちらを利用する形で実装はできましたが、肝心のポジションの取り方についてドメイン知識がないのもあり、あれもこれも手を出しても無理なので、ひとまず撤退しました。
公営競技AIと異なる点として、有識者による情報共有が (これらと比べると) 盛んで、例えば過去エッジがあった手法の共有や考え方、分析した結果などを公開されている方がいたりします。また時間があれば、知識つけてからエッジを探す旅に出たいと思っています。
ポーカー
きっかけはYoutubeで、ポーカーという競技に興味を持ちました。 自分が高校生ぐらいの頃からe-sportsプロがポーカープロに転向していくのを観測していて存在は知っていたのですが、日本でここまで流行ってるとは知らなかったので驚きました。
↓の書籍を読みつつ、解説動画や記事を参考にポーカーチェイスというオンラインゲームで遊んでます。オフラインだと渋谷のROOTSに遊びに行ったり、JOPTのサテライトのトナメに参加したりしました。 https://www.amazon.co.jp/%E3%82%A8%E3%83%89%E3%83%BB%E3%83%9F%E3%83%A9%E3%83%BC%E3%81%AE%E3%83%9D%E3%83%BC%E3%82%AB%E3%83%BC%E3%82%B9%E3%82%AF%E3%83%BC%E3%83%AB-%E2%94%80%E2%94%80%E3%83%A9%E3%82%A4%E3%83%96%E3%82%B2%E3%83%BC%E3%83%A0%E3%81%A7%E5%8B%9D%E3%81%A4-%E3%82%AB%E3%82%B8%E3%83%8E%E3%83%96%E3%83%83%E3%82%AF%E3%82%B7%E3%83%AA%E3%83%BC%E3%82%BA-%E3%82%A8%E3%83%89%E3%83%BB%E3%83%9F%E3%83%A9%E3%83%BC/dp/4775949179
暫定1位のスクショ、結果は6/648位でした。
まだまだ初心者なので、もっと勉強して来年は色々なトナメ出ようと思ってます。そして機会あれば、ラスベガスとかでキャッシュゲーム打ちたいなって気持ちです。
2021年の雑感
今年の振り返り
をしていこうと思いましたが、驚くことに、前回の記事から1年が経とうとしているようです。
今年も起こった出来事や仕事、趣味などについて、覚えている範囲で書き起こそうと思います。恐らく趣味ばっかりになると思います。
昨年たてた目標の振り返り
直近はJANOG47のイベントを成功させることと、仕事で直面している問題を考えたアプローチ解決すること、Kafkaのお勉強をして資料を作ること
達成しました
Rustを学び始めることをやっていきます。時間が出来たら、関数型言語のお勉強と競プロの問題解くのをしたいです。
達成できませんでした、もっと勉強しようね
来年の抱負
先に抱負から書こうと思います。
組織の体制が大幅に変わるので、それに順応しつつ日々の開発を安全に進めていきたいです。自分は10月から現チームのテックリードとなりましたが、新しいチームが発足したため半数以上のチームメンバが異動することとなります。
それと同時に、良いチームとは何か、良いチームを作るにはどうするべきか、を日々悶々と考えています。 自分が考える良いチームの定義の一つは、可能な限り全てのメンバが全ての業務を担えるような状況になれることです。立場上不可能なこともありますが、例えばできるかぎり情報を共有してチームとして意思決定するであるとか、特定の人だけが担っていた開発を他の人も担えるようにするとかを指します。
現状「特定のオペレーションはxxさんしか知らない」といったことが起こっているので、xxさんが何らかの理由でチームを離れることになった場合、破綻してしまいます。なので、こうしたナレッジを個々人でなくチームとして管理できるようになると、xxさんが担当でなくなってもナレッジはチームに残り続けるので移譲にはそれほど労力を割かなくて良いと考えます。
まだまだ何が良いチームなのかを手探りで考えながら過ごす日々が続くと思いますが、来年も障害など起こさずに開発に従事していければと思います。
あと、ブログは定期的に投稿するようにしたいですね。
1月~3月
この頃から毎週実施している週次リリースに向けたPRレビューや準備 (他サービスとの依存関係やリリース順序の確認、本番での検証、ロールバックプランとか) をメインで担当するようになりました。同時にメンバから上がってくる機能開発系や改善系のPRレビューであったり、様々なPJの自サービスの開発者として他チームと相談しながらハイレベルなデザインを決めてメンバにタスクをアサインすることを引き続き実施していました。当時のテックリードの助けもあり、本番環境で特に障害を起こすことなく運用できました。
ウマ娘プリティーダービーを遊んでいた頃でした。これがきっかけとなり競馬に興味を持ち始めます。
函館に旅行しました、食事も美味しいし観光楽しいしで良い旅になりました。



4月~6月
4, 5月ごろになると、釣り友達みんなで相模湾にLT五目釣りをしにいきました。茅ヶ崎の漁港は非常に活気があって、船長やお店の人も親切なのでとても楽しめました。2回目以降乗船する時には、既に顔を覚えられていたのがちょっと驚きでした。顔を覚えられていたりすると、また利用したくなりますね。

あんまり覚えてないですが、伊豆大島にもこの辺で釣りに行ったと思います。大漁にエソとカンパチを釣って、カンパチだけ持って帰ってきました。
皐月賞あたりから競馬を始めました。競馬は過去データが豊富且つ整備されていおり、機械学習向けのコンテンツです。面白そうなので、着順を予想する競馬AIの開発に取り組みはじめました。
詳細は割愛しますが、シミュレーション上だと回収率がプラスになる買い方をリアルで検証してみたところ、シミュレーション通りの結果になりませんでした。恐らく利用している未来データが過去レースデータと比べて欠損が多かったり、何らかのリークが考えられますが、原因を探しているところです。
特徴量エンジニアリングするにはやはりドメイン知識をつけることが必要不可欠なので、ここから競馬の知識を仕入れることとなります。
7月~9月
仕事内容に関してはあまり変化はありませんでしたが、超忙しかったです。(絶望)
船釣りでジギングしにいきましたが、まさかの坊主をキメました。 去年の夏もジギングで坊主だった気がする..夏にジギング船に乗らないほうがいいのでは?
また別日では金沢八景でLTアジ午後船にのって、こちらは爆釣しました。
引っ越しをして、今は川崎に住んでいます。洗濯物が干しても乾かないので、ドラム式洗濯機を買いました。

10月~12月
10月から今のチームのテックリードとして働くことになりました。意思決定の裁量が増え、チームのマネジメントにも時間を割く必要がでてきます。移譲可能なタスクはチームメンバ達にどんどん任せ、自分は自分もしかできないことに時間を割くよう立ち回り始めました。
シルバーウィークは初めて鹿児島に訪れました。 桜島をふらっと観光してから、フェリーで屋久島に上陸しました。 自分は全然魚が釣れなくて信じられなかったのですが、友達らと12時間弱かけて屋久杉+太鼓岩を見る登山をやりました。筋肉痛が4日引かなかったので、この後地獄を見ることになります。

鹿児島の芋焼酎はとても美味しかったですね、度数がめちゃ高かったですが





毎年恒例のカワハギ釣りにでかけ、今年は山下丸とみのすけ丸にお邪魔しました。爆釣して肝パンのカワハギを何枚も釣れたので、大満足でした。

健康診断の結果が悪化してたので、体が運動を求めます。 散歩するモチベーションのためにドラクエウォークを始めました。始めてから4kgほど痩せたので、引き続きスキマ時間で散歩しまくる生活を続けていきます。
11月は初めて競馬場に訪れることとなりました。
東京競馬場でジャパンカップを生で見て、コントレイルの引退式にも参加できたのはとても思い出深いです。


オンラインでも度々レースを予想して勝って負けてを繰り返していましたが、ホープフルSで取り戻して今年は終いとなりました。
このレースは冷静じゃない賭け方してますが、キラーアビリティには自信がありました。


並行して一口馬主を始めました。
自分が出資したのは2頭でラブリーベルナデット20とフォークロア20です。
今年のセリで非常に高い値段のついたキズナ産駒、日本で好走しているArrogate産駒はデータ的にも勝利割合が高いので、この2頭にしました。
自分が応募した名前が採用されてほしいなぁ

JANOG49に復活をとげたNETCONが開催されるようです。今年は自動採点を一部の問題に対して実施しようとしていて、その辺りの開発をやってます。うまくいくといいね
2020年の雑感
今年の振り返り
をしようと年を越す1時間半前に思い立ったので、今年起こった出来事や仕事、趣味などについて、覚えている範囲で書き起こそうと思います。

1~3月
所属している会社で新規決済フローの開発に携わらせて頂いたりしていました。他には週ごとのリリースに応じた日常的な開発であったり、幾つかのリファクタリングのPRなど上げたりしていたと思います。 ちょうどこの頃に春以降のチームの体制が変わることを知り、不安もありましたが、頑張ろうという気持ちで日々過ごしていました。
群馬のイワナセンターに初めて釣りに行ったのがこの頃でした。めちゃめちゃ釣れますし、個体が大きいです。ここで釣れたトラウトのサーモンが美味しいので、この後も通うことになります (12月に続く)
4~6月
自分がコミットしているサービス(BFF)は元々Native app向けのサービスでしたが、クライアント多様化に伴い、アーキテクチャの見直しの必要に迫られました。 特にエラーハンドリング周りが複雑になることが予見されていたので、各クライアントごとに異なる表示要件を満たせるような仕組みを実装して、そちらに移行していく作業を全APIに対して行いました。具体的には新たに設けたfactory内でエラーコードやclient typeといったパラメータの組み合わせごとにクライアントに返すべきenumを予め決定し、その後でエラーレスポンスを作るという形になりました。現12月時点でAPIの数が250を超えているので、こうした作業を確実にこなすのは骨が折れましたが、特に問題もなくmigrationすることができました。 また、それとは別の話で、Native appが保持しているロジックを可能な限り自サービスに移すリファクタリングや週ごとの機能改善・開発などをこなしていました。このロジック移管は秋〜冬あたりまで長く続くものとなりました。 新しいメンバーがジョインして、チームの体制が少しずつ変わっていきます。
釣りに関してははっきりと覚えていませんが、伊豆諸島か横須賀沖のどちらかに居たはずです。 そして体重が徐々に増えていきます。
7~9月
新規機能の開発や既存機能の修正にコミットしていました。また上記のリファクタリングであったり、他サービスのAPIを新しいエンドポイントにmigrateするといった開発など取り組んでいました。諸事情で、この時作ったものでまだ世にリリースされていない機能があるので、来年はリリースされると嬉しいですね。 既存機能にがっつり修正を入れた場合に、機能がdegradeしていないことを保証することがとても難しいですが、徹底的にテストすることで僕は担保していました。 (実際にはYou're looking for a needle in a haystack.かもですね..) 新しいメンバーがジョインして、チームの体制が少しずつ変わっていきます。(2回目)
初めて神津島に上陸しました。カンパチのショゴが無限に釣れてヤバいじゃんこの島となりました。ワンチャン離島に住みたいです。 また、2週間で3回横須賀沖にいる実績を解除しました。在宅勤務なのに肌の色だけ黒い歪な人間として過ごす業を背負います。
あとTutterとかいうサービスを密かに作りました、これで魚拓を取ることが出来ます。 tutter.org
また、なぜか1~3月期と比べて体重が+5kgほどしました。
10~12月
コアな決済機能にがっつり修正を入れるプロジェクトや大型の新規機能開発のプロジェクト、日々の開発業務等が並列で走っていてめちゃ多忙でした。脳みそのコンテキストスイッチ上級者編です。 今年学んだことの一つとして、「このリファクタは後でやろう」は99%やれないと思います。特に忙しいと絶対無理です。なので新規機能であれば開発時に無理にでもmasterにマージできるよう持っていくほうが後々の改修コストを回収 (←ここ激ウマギャグ) できるのではないかと思い始めています。既存のものでも、チームで議論して、将来を見据えて今変えるべきであれば変えたほうがいいと思います。 年末は長い間やりたかったリファクタであったり、抱えている問題(外部API使うと1億円かかるから自前で何とかする)を解決するアイディアを検証するといったことに着手できて負債を少しは返済できたんじゃないかなと思います。 新しいメンバーがジョインして、チームの体制が少しずつ変わっていきます。(3回目)
お誘い頂いたのもあり、JANOG47に初参加することになりました。運営としてNETCON準備のためのサーバ開発(VMとか管理する用のAPIサーバ)に取り組んでいます。会社以外の人々と開発する機会はとても貴重ですし、ワイワイ作るのは楽しいので、参加してよかったと思います。 これらで忙殺されそうになっていたところをごちうさ3期とyoutubeに救われました。
この時期には二度目の神津島とイワナセンターへの釣行、八丈島、そしてカワハギ釣りに行くことができました。特にカワハギ釣りは去年参加することができず、今年初参加でしたが、初めて一匹釣ったときは本当に嬉しかったです。
BMI指数が22.5(?)ぐらいになってしまったのでリングフィットアドベンチャーでダイエットを試みますが、仕事と諸々の作業や勉強のため断念します。体重は減りませんでしたが、体脂肪率が減ったため、ぽっこりお腹が少し解消されました。
来年の抱負
人生として好き勝手できる時間も限られていますので、来年はもっと勉強に身を入れていきたいです。 直近はJANOG47のイベントを成功させることと、仕事で直面している問題を考えたアプローチ解決すること、Kafkaのお勉強をして資料を作ること、Rustを学び始めることをやっていきます。時間が出来たら、関数型言語のお勉強と競プロの問題解くのをしたいです。
Effective Javaを読んでまとめてみる その2
Item6 : 不要なオブジェクトを作らないこと
極力immutableにすること
ng String s = new String(hoge);
ok String s = "hoge";
また, static factory methodsを使ってもimmutableなオブジェクトを作ることができる.
ng 正規表現のmatchs() は呼ばれる度に内部でpattern instanceを生成するため, 繰り返し呼ばれる処理では実施すべきでない.
ok compile()で事前にpattern instanceを生成すること.
ng autoboxing e.g., Booleanで定義されたものを, primitiveであるbooleanで使う boolean -> Booleanはboxing, Boolean -> booleanはunboxingと呼ばれ, 非効率 基本的にはboxedな型を使う.
Item 7 : obsolete referenceを消すこと
public Object pop() {
if (size == 0)
throw new EmptyStackException();
Object result = elements[--size];
elements[size] = null; // Eliminate obsolete reference
return result;
}
popされたobjectがgcされない 配列確保してドンドン拡張するだけ
明示的にnullを入れてあげることでgcにより解放される
他にメモリリークが起きやすいのは, Cache(例. lifecycleの設定が長すぎる)やAPI clientなどのlisteners/callbacksである.
Item 8 : finalizer/cleanerを使わないこと
例として, try-catch-final や deconstructorが挙げられる.
これらは意図しない挙動や性能悪化の観点から使わないほうがよい.
例えばdeconstructする際には, gcが解放予定の領域が参照されていないことを確認した上でメモリ領域解放するので, ただ単に解放を行うC++と比べて遅い.
cleanerのコード
adult mainのコード
このように, 環境によって振る舞いがことなる
Item 9 : try-finallyよりtry-with-resourcesを使うこと
try-finallyのtryでexceptionを投げた場合, finallyにあるcloseは失敗する
安全にcloseするには try-with-resources
Item 10 : equals()をoverrideする時はgeneral contractに従うこと
以下の時はequals()をoverrideしてはいけない:
して良いのは, そのclassがオブジェクト的に等価であるよりも論理的に等価であることを考えたい時で, かつ親クラスが既にoverrideしていない時である
-> String, Integerといった値クラスが該当 ただしenumはoverrideしなくてよいvalue classである
equals()をOverrideする時は以下のcontract(契約)に準ずる:
Item 11 : equals()をoverrideする時はhashCode()もoverrideする
hashCodeをoverrideしなければ, hashCodeのgeneral contractに違反する. contractは以下である: - 同じ引数で呼ばれたら必ず同じ値を返す, hashCode(A) = hashCode(A) - オブジェクトA.equal(オブジェクトB)がtrueなら, hashCodeは同じintegerになる
等価なオブジェクトは等価なhashCodeを持つ
ObjectsクラスにObjects.hashというmethodがある. これを利用することでhashCode()を簡単にかけるが, 性能が悪く遅いので注意.
クラスがimmutableでhash codeの計算コストを抑え性能を出したいならば, 結果をcacheすると良い.
// hashCode method with lazily initialized cached hash code
private int hashCode; // Automatically initialized to 0
@Override public int hashCode() {
int result = hashCode;
if (result == 0) {
result = Short.hashCode(areaCode);
result = 31 * result + Short.hashCode(prefix);
result = 31 * result + Short.hashCode(lineNum);
hashCode = result;
}
return result;
}
Bloch, Joshua. Effective Java (p.53). Pearson Education.
Item 12 : toStringは常にoverrideすること
When practical, the toString method should return all of the interesting information contained in the object,
PhoneNumber@adbbd vs 606-293-3293 後者のほうが自明.
toString()は様々なところで利用されるので, 一度決めてしまうと変更しづらい. (大量のハレーションが起こる) そのため, フォーマットを明確にすべき.
Whether or not you specify the format, provide programmatic access to the information contained in the value returned by toString. For example, the PhoneNumber class should contain accessors for the area code, prefix, and line number.
これをしないと, そのクラスのユーザが独自にgetして好きにフォーマットすることができなくなってしまうため, と思われる.
Item 13 : cloneは場合に応じてoverrideすること
cloneはClonableをimplementすることで利用できる
ただしimmutableクラスはcloneメソッドを提供するべきでないので, mutableにする必要がある
cloneを実装する時はeepCopyすること, つまりcloneされたオブジェクトを変更した場合に, その変更内容がオリジナルに波及しないことが大切である. 例えば以外のelementa配列は同じオブジェクトになりうる:
public class Stack {
private Object[] elements;
private int size = 0;
private static final int DEFAULT_INITIAL_CAPACITY = 16;
public Stack() {
this.elements = new Object[DEFAULT_INITIAL_CAPACITY];
}
public void push(Object e) {
ensureCapacity();
elements[size++] = e;
}
public Object pop() {
if (size == 0)
throw new EmptyStackException();
Object result = elements[--size];
elements[size] = null; // Eliminate obsolete reference
return result;
}
// Ensure space for at least one more element.
private void ensureCapacity() {
if (elements.length == size)
elements = Arrays.copyOf(elements, 2 * size + 1);
}
}
これを解決する最も簡単な記述は以下:
// Clone method for class with references to mutable state
@Override public Stack clone() {
try {
Stack result = (Stack) super.clone();
result.elements = elements.clone();
return result;
} catch (CloneNotSupportedException e) {
throw new AssertionError();
}
}
しかしこの方法は, elements fieldがfinalの場合うまくいかない.
このように一般的に, Cloneable アーキテクチャは mutableオブジェクトを参照するfinal fieldsを持つような使い方と相性がよくない.
またclone()をoverrideしたメソッドは CloneNotSupportedException (checked exceptionの一種)を投げなくてもよい. checked exceptionに関する記述を都度行うのは大変なので, 記述しなくてよい.
clone()をoverrideする上でよりよいオブジェクトのコピー方法は, copy constructorかfactoryを提供すること.
public Yum(Yum yum) { ... };
or
public static Yum newInstance(Yum yum) { ... };
Item 14 : Comparableの実装を考慮すること
compareTo()の話
- 利点1 : Comparableをimplementsすることで, そのインスタンスは自然な順序であることを明示できる.
以下に, アルファベット順にコマンドライン引数を重複なしで出力する例を示す. ここではStringがComparableをimplementしている.
public class WordList {
public static void main(String[] args) {
Set<String> s = new TreeSet<>();
Collections.addAll(s, args);
System.out.println(s);
}
}
- 利点2 : そのクラスが, 多くのgenericなアルゴリズムやcollectionの実装を使うことができるようになる.
compareTo()のgeneral contractは3つあり, equals()と似ている:
sgn() : signum function returns -1, 0 or 1. sgn(x.compareTo(y)) == -sgn(y. compareTo(x))
x.compareTo(y) > 0 && y.compareTo(z) > 0 ならば x.compareTo(z) > 0
sgn(x.compareTo(z)) == sgn(y.compareTo(z)) for all z
(Not required but strongly recommended) (x.compareTo(y) == 0) == (x.equals(y)) もしこれを満たさないなら以下の文言を入れるべきである. “Note: This class has a natural ordering that is inconsistent with equals.”
CollectionsやArraysクラス, TreeSetやTreeMapといったデータ構造のクラスはcomparisonに依存しているので, 上記のgeneral contractを満たさないと壊れる. 基本的にequals()と同じ制約に従わないとダメ.
また冗長になるので, compareTo()の実装で>や<を使うのは避けるべき.
Item 15 : クラスやそのメンバへの参照は最低限にすること
private, package-private, protected, publicの設定を適切にしましょう. バグらせたりユーザを混乱させたりして開発速度やコードの品質を落とさないために.
メンバは基本privateを使う, 使わないmutableなメンバを含むクラスはthread safeでないと考えるべき.
1以上の長さの配列は常にmutableなので, public static finalなarray fieldとして定義したり, アクセサを用意するのは間違い.
// Potential security hole!
public static final Thing[] VALUES = { ... };
これを解決するのは, public で immutableなリストを作って, それに詰め替える.
private static final Thing[] PRIVATE_VALUES = { ... };
public static final List<Thing> VALUES =
Collections.unmodifiableList(Arrays.asList(PRIVATE_VALUES));
private で immutableなリストを作って, それに詰め替え, アクセサを用意する.
private static final Thing[] PRIVATE_VALUES = { ... };
public static final Thing[] values() {
return PRIVATE_VALUES.clone();
}
Item 16 : publicなfieldよりもpublicなアクセサを使うこと
ng
// Degenerate classes like this should not be public!
class Point {
public double x;
public double y;
}
ok
// Encapsulation of data by accessor methods and mutators
class Point {
private double x;
private double y;
public Point(double x, double y) {
this.x = x;
this.y = y;
}
public double getX() { return x; }
public double getY() { return y; }
public void setX(double x) { this.x = x; }
public void setY(double y) { this.y = y; }
}
Item 17 : mutabilityを最小限にすること
利点: 設計, 実装, 利用するのが簡単になる
immutable classにする条件は以下の5つを守ること:
- オブジェクトの状態を変えられるようなメソッドを提供しない
- extendされないことを保証する
- すべてのfieldにfinalをつける memory model [JLS, 17.5; Goetz06, 16] : 同期せずに新しく作成されたインスタンスが別スレッドに渡されること の場合は必須
- すべてのfieldをprivateにする
- mutable componentの参照は限定的にする
// Immutable complex number class
public final class Complex {
private final double re;
private final double im;
public Complex(double re, double im) {
this.re = re;
this.im = im;
}
public double realPart() { return re; }
public double imaginaryPart() { return im; }
public Complex plus(Complex c) {
return new Complex(re + c.re, im + c.im);
}
public Complex minus(Complex c) {
return new Complex(re - c.re, im - c.im);
}
public Complex times(Complex c) {
return new Complex(re * c.re - im * c.im,
re * c.im + im * c.re);
}
public Complex dividedBy(Complex c) {
double tmp = c.re * c.re + c.im * c.im;
return new Complex((re * c.re + im * c.im) / tmp,
(im * c.re - re * c.im) / tmp);
}
@Override public boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Complex))
return false;
Complex c = (Complex) o;
// See page 47 to find out why we use compare instead of ==
return Double.compare(c.re, re) == 0
&& Double.compare(c.im, im) == 0;
}
@Override public int hashCode() {
return 31 * Double.hashCode(re) + Double.hashCode(im);
}
@Override public String toString() {
return "(" + re + " + " + im + "i)";
}
immutableの代表的な欠点は, 異なるオブジェクトを作る時に必ず生成する必要があること. 例えば整数で1bitズラしたい場合も新しいオブジェクトとして生成する必要があるが, mutableなオブジェクトは生成せずにただズラすだけでよい. オブジェクトが巨大になればなるほど, 生成にかかるコストが増える.
Item 18 : 継承よりもcomposition
継承はpackageを跨がず, 同一プログラマのみがsub classに使う場合やドキュメンテーションがなだれている場合には問題ないが, そうでない場合には問題になりやすく危険である. 継承はカプセル化に違反する.
継承は実装を共通化するという目的のためだけに使うものではない. 継承を行うと, classに修正が入った場合, そのsub classも修正する必要がある. 修正の手間を減らすため, class sub classが別々に定義されうるかもしれない. これは最悪である.
継承で意図しない例を以下に示す
// Broken - Inappropriate use of inheritance!
public class InstrumentedHashSet<E> extends HashSet<E> {
// The number of attempted element insertions
private int addCount = 0;
public InstrumentedHashSet() {
}
public InstrumentedHashSet(int initCap, float loadFactor) {
super(initCap, loadFactor);
}
@Override public boolean add(E e) {
addCount++;
return super.add(e);
}
@Override public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return super.addAll(c);
}
public int getAddCount() {
return addCount;
}
}
以外のコードを実行すると, カウントは3でなく6になる.
最初にHashSetのaddAll()が呼ばれ, 更にその中でオーバーライドしたImplemented-HashSetのaddAll()が呼ばれる. 次にHashSetのaddAll()の中では, add()が3回呼ばれる. そしてそれをオーバライドしたImplemented-HashSetのadd()が3回呼ばれるので, 3 + 1*3の6となる.
この順序自体は保証されているものではばく, 今後のリリースでHashSetの実装が変わることがありうる. 変わるたびに影響を受けるため, Implemented-HashSetクラスは簡単に壊れやすい.
また, super classにメソッドが追加された場合を考えてみる. こうしたケースでは同様のメソッドがImplemented-HashSetクラスに継承されてしまうため,破壊されるだろう.
composite designを使うとこの問題を回避できる. compositeは既存のクラスを参照するprivate fieldを持つことで, 合体する(包含する)ようなWrapperクラスを作る.
以下に例を示す:
// Wrapper class - uses composition in place of inheritance
public class InstrumentedSet<E> extends ForwardingSet<E> {
private int addCount = 0;
public InstrumentedSet(Set<E> s) {
super(s);
}
@Override public boolean add(E e) {
addCount++;
return super.add(e);
}
@Override public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return super.addAll(c);
}
public int getAddCount() {
return addCount;
}
}
// Reusable forwarding class
public class ForwardingSet<E> implements Set<E> {
private final Set<E> s;
public ForwardingSet(Set<E> s) { this.s = s; }
public void clear() { s.clear(); }
public boolean contains(Object o) { return s.contains(o); }
public boolean isEmpty() { return s.isEmpty(); }
public int size() { return s.size(); }
public Iterator<E> iterator() { return s.iterator(); }
public boolean add(E e) { return s.add(e); }
public boolean remove(Object o) { return s.remove(o); }
public boolean containsAll(Collection<?> c)
{ return s.containsAll(c); }
public boolean addAll(Collection<? extends E> c)
{ return s.addAll(c); }
public boolean removeAll(Collection<?> c)
{ return s.removeAll(c); }
public boolean retainAll(Collection<?> c)
{ return s.retainAll(c); }
public Object[] toArray() { return s.toArray(); }
public <T> T[] toArray(T[] a) { return s.toArray(a); }
@Override public boolean equals(Object o)
{ return s.equals(o); }
@Override public int hashCode() { return s.hashCode(); }
@Override public String toString() { return s.toString(); }
}
Item 19 : 継承を使うなら設計してドキュメンテーションすること, そうでなければ禁止すること
self-useのoverride可能なmethodにはドキュメンテーションを強いることが大切.
public boolean remove(Object o) のドキュメンテーションの例を以下に示す:
存在するならば, 単一のインスタンスをコレクションから除く. より一般的には, 1つ以上の要素がある場合, Objects.equals(o, e)のような要素eを除く. そして指定された要素が含まれている場合はtrueを返します. Implementation Requirements: この実装では特定要素を探し出すためにコレクションを探索します. もし要素を見つけたら, iteratorのremove()を用いて削除します. 特定オブジェクトが含まれておらず, コレクションのiteratorにremove()が実装されていない時, コレクションのiteratorによってUnsupportedOperationExceptionを投げることに注意してください.
このドキュメントであれば, iteratorのmethodをoverrideすることがremove()の振る舞いに影響を与えないことが分かる.
「継承を設計する」はドキュメンテーションを含む. プログラマに効率のよいsub classを書かせるためには, classは慎重にprotectedにされたフォームの内部動作のフックを提供する必要がある.
protected void removeRange(int fromIndex, int toIndex) Removes from this list all of the elements whose index is between fromIndex, inclusive, and toIndex, exclusive. Shifts any succeeding elements to the left (reduces their index). This call shortens the list by (toIndex - fromIndex) elements. (If toIndex == fromIndex, this operation has no effect.) This method is called by the clear operation on this list and its sublists. Overriding this method to take advantage of the internals of the list implementation can substantially improve the performance of the clear operation on this list and its sublists. Implementation Requirements: This implementation gets a list iterator positioned before fromIndex and repeatedly calls ListIterator.next followed by ListIterator.remove, until the entire range has been removed. Note: If ListIterator.remove requires linear time, this implementation requires quadratic time. Parameters: fromIndex index of first element to be removed. toIndex index after last element to be removed.
removeRange()はユーザが与えるListには興味がなく, ただ高速なclear()をsub listに提供する.
継承のための設計においてどのメンバをpublic/protectedにすべきか?という問いの答えは一概に言えない. 少なすぎても継承のために利用可能なメンバが少なすぎて実用的でなくなるし, メンバらは実装の詳細における契約となっているため, 多すぎるとクラスが意味をなさなずに継承しにくくなる.
継承を設計されたクラスをテストする唯一の方法は, sub classを書くことである. リリースする時にはドキュメントを作るだとか, パフォーマンスを改善するというのは到底難しいので, リリース前にはsub classを書いてテストすること.
Item 20 : abstract classよりinterfaceを好むこと
既に存在しているクラスであれば, 新しいinterfaceを実装して改良するほうが楽. interfaceはmixinの理想形.
public interface Singer {
AudioClip sing(Song s);
}
public interface Songwriter {
Song compose(int chartPosition);
}
利点: 非階層な型フレームワークのconstructが可能
SingerとSongwriteを兼ね備えるとすると, 両方をextendsすることが出来る.
public interface SingerSongwriter extends Singer, Songwriter {
AudioClip strum();
void actSensitive();
}
Item 18で述べたwrapper classを用いることで, interfaceは安全で機能的に優れている. abstract classを使って型を定義すると, wrapper classを使うよりも壊れやすくなる. (Item 18で述べた通り)
abstract classの利点は, default methodを提供できるところである
abstract classとinterfaceの良いとこ取りをして合体させたクラスを skeletal implementation classという. これを用いると型をinterfaceで定義し, default methodを持つことができる.
例えば以下のintArrayAsList()を考える.
// Concrete implementation built atop skeletal implementation
static List<Integer> intArrayAsList(int[] a) {
Objects.requireNonNull(a);
// The diamond operator is only legal here in Java 9 and later
// If you're using an earlier release, specify <Integer>
return new AbstractList<>() {
@Override public Integer get(int i) {
return a[i]; // Autoboxing (Item 6)
}
@Override public Integer set(int i, Integer val) {
int oldVal = a[i];
a[i] = val; // Auto-unboxing
return oldVal; // Autoboxing
}
@Override public int size() {
return a.length;
}
};
}
これをskeletal implementationで実装すると以外になる. skeletal implementationであってもドキュメンテーションは必須である.
// Skeletal implementation class
public abstract class AbstractMapEntry<K,V>
implements Map.Entry<K,V> {
// Entries in a modifiable map must override this method
@Override public V setValue(V value) {
throw new UnsupportedOperationException();
}
// Implements the general contract of Map.Entry.equals
@Override public boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry) o;
return Objects.equals(e.getKey(), getKey())
&& Objects.equals(e.getValue(), getValue());
}
// Implements the general contract of Map.Entry.hashCode
@Override public int hashCode() {
return Objects.hashCode(getKey())
^ Objects.hashCode(getValue());
}
@Override public String toString() {
return getKey() + "=" + getValue();
}
}
Item 21 : 後々のためにinterfaceを設計すること
Java8から, 多くの汎用的に使えるdefault methodsが導入されたが, そのまま利用できないケースもある.
default methodsが存在する中で, interfaceのimplementationの中身を同時に書くことは, 実行時エラーになる可能性がある. なのでdefault methodsは不要なら含むべきでない.
Item 22 : 型を定義するためにinterfaceを使うこと
以下のようなconstant interfaceは使ってはいけない.
// Constant interface antipattern - do not use!
public interface PhysicalConstants {
// Avogadro's number (1/mol)
static final double AVOGADROS_NUMBER = 6.022_140_857e23;
// Boltzmann constant (J/K)
static final double BOLTZMANN_CONSTANT = 1.380_648_52e-23;
// Mass of the electron (kg)
static final double ELECTRON_MASS = 9.109_383_56e-31;
}
このようなinterfaceの使い方はしょぼくて意味がないので, interfaceを使わずに以下のようにする.
// Constant utility class
package com.effectivejava.science;
public class PhysicalConstants {
private PhysicalConstants() { } // Prevents instantiation
public static final double AVOGADROS_NUMBER = 6.022_140_857e23;
public static final double BOLTZMANN_CONST = 1.380_648_52e-23;
public static final double ELECTRON_MASS = 9.109_383_56e-31;
}
static importを使うとクラス名を持つ定数の名前の妥当性確認を行わずに利用できるので, 利用頻度が高い場合にはstatic importで定数のクラスをimportすると良い.
Item 23 : タグ付けしたclassよりも階層的なclassを好むこと
タグ付けは例えばコメントでfieldの使用方法が書くことで, 以下のようなクラスを指す.
コード
これよりもinheritanceを用いて階層的なクラスを作る
コード
Item 24 : non staticよりもstaticなmember classを好むこと
non staticなmember classのインスタンスは, 暗にそのmemberを含むclass(enclosing class)のinstanceに関係を持っていることを示す. なので, enclosing classのinstanceを参照する必要がないのであれば, staticをつけること.
利点: staticをつけてenclosing instanceからの参照を隠すことで, gcが効くようになる. non staticだとgcされず, enclosing instanceに保持され続けるかもしれない.
Item 25 : ソースファイルを一番上の単一のクラスにすること
以下のようなクラスは一つのソースファイルにまとめないこと.
// Two classes defined in one file. Don't ever do this!
class Utensil {
static final String NAME = "pot";
}
class Dessert {
static final String NAME = "pie";
}
Item 26 : raw typeを使わないこと
ng
// Raw collection type - don't do this! // My stamp collection. Contains only Stamp instances. private final Collection stamps = ... ;
以下のように書くと, コンパイルは通るがstamp collectionからcoinを検索する時にエラーを吐く.
// Erroneous insertion of coin into stamp collection stamps.add(new Coin( ... )); // Emits "unchecked call" warning
// Raw iterator type - don't do this!
for (Iterator i = stamps.iterator(); i.hasNext(); ) {
Stamp stamp = (Stamp) i.next(); // Throws ClassCastException
stamp.cancel();
}
ok
// Parameterized collection type - typesafe private final Collection<Stamp> stamps = ... ;
raw typeを使う欠点 1. 安全でなくなる 2. genericsを使えない
このルールに当てはまらない例外として, class literalではraw typeを使うこと. ok
List.class, String[].class, and int.class
ng
List<String>.class and List<?>.class
同様にinstanceof 演算子ではraw typeを使うこと.
// Legitimate use of raw type - instanceof operator
if (o instanceof Set) { // Raw type
Set<?> s = (Set<?>) o; // Wildcard type
...
}
Item 27 : unchecked warningsを消すこと
以下のコードはunchecked warningsを吐く.
ng
Set<Lark> exaltation = new HashSet();
<>をつけると型推論してくれる.
ok
Set<Lark> exaltation = new HashSet<>();
可能な限りunchecked warningsを除き, 除ききれないものについては型安全であることを証明し, @SuppressWanrning("unchecked")アノテーションをつけること. (このアノテーションはその時にのみ使われること.)
@SuppressWanrning("unchecked")のスコープは最小にすること.
@SuppressWanrning("unchecked")を使うときは「何故安全なのか」のコメントを入れること.
Item 28 : arrayよりもlistを好むこと
例えば
String[]
と
List<String>
であれば,後者のlistが型安全の観点で良い.
前者のarrayはLongの要素を入れようとしてしまうと, ArrayStoreExceptionを吐く. 一方でGenericsである後者は異なる型の要素が入らないことを保証しているので, こうした間違いをコンパイル時に防ぐことができる.
// List-based Chooser - typesafe
public class Chooser<T> {
private final List<T> choiceList;
public Chooser(Collection<T> choices) {
choiceList = new ArrayList<>(choices);
}
public T choose() {
Random rnd = ThreadLocalRandom.current();
return choiceList.get(rnd.nextInt(choiceList.size()));
}
}
Item 29 : Genericを好むこと
// Initial attempt to generify Stack - won't compile!
public class Stack<E> {
private E[] elements;
private int size = 0;
private static final int DEFAULT_INITIAL_CAPACITY = 16;
// The elements array will contain only E instances from push(E).
// This is sufficient to ensure type safety, but the runtime
// type of the array won't be E[]; it will always be Object[]!
@SuppressWarnings("unchecked")
public Stack() {
elements = (E[]) new Object[DEFAULT_INITIAL_CAPACITY];
}
public void push(E e) {
ensureCapacity();
elements[size++] = e;
}
// Appropriate suppression of unchecked warning
public E pop() {
if (size == 0)
throw new EmptyStackException();
// push requires elements to be of type E, so cast is correct
@SuppressWarnings("unchecked") E result =
(E) elements[--size];
elements[size] = null; // Eliminate obsolete reference
return result;
}
... // no changes in isEmpty or ensureCapacity
}
Item 30 : generic methodsを好むこと
ng
// Uses raw types - unacceptable! (Item 26)
public static Set union(Set s1, Set s2) {
Set result = new HashSet(s1);
result.addAll(s2);
return result;
}
ok
// Generic method
public static <E> Set<E> union(Set<E> s1, Set<E> s2) {
Set<E> result = new HashSet<>(s1);
result.addAll(s2);
return result;
}
Item 31 : APIの柔軟性を高めるために, bounded wildcardsを使うこと
以下のstackに pushAll() を加えたいとする.
public class Stack<E> {
public Stack();
public void push(E e);
public E pop();
public boolean isEmpty();
}
wildcard typeを使わないコードが以下である.
// pushAll method without wildcard type - deficient!
public void pushAll(Iterable<E> src) {
for (E e : src)
push(e);
}
この問題点は, 論理的に同じ型であっても動かないことである.
例えば Stack<Number> を持っていて, push(intVal) することを考える. intValはInteger型であり, IntegerはNumberのsubtypeであるので論理的には動くはずである.
しかしながら, これは実際には動作しない.
wildcardを使って以下のように書く必要がある.
// Wildcard type for a parameter that serves as an E producer
public void pushAll(Iterable<? extends E> src) {
for (E e : src)
push(e);
}
Item 32 : genericsとvarargsを賢く組み合わせること
generics varargsに値をstoreするのは安全でない. ng
// Mixing generics and varargs can violate type safety!
static void dangerous(List<String>... stringLists) {
List<Integer> intList = List.of(42);
Object[] objects = stringLists;
objects[0] = intList; // Heap pollution
String s = stringLists[0].get(0); // ClassCastException
}
ok
// Safe method with a generic varargs parameter
@SafeVarargs
static <T> List<T> flatten(List<? extends T>... lists) {
List<T> result = new ArrayList<>();
for (List<? extends T> list : lists)
result.addAll(list);
return result;
}
Item 34 : int型の定数の代わりにenumを使うこと
以下のように使う
// The int enum pattern - severely deficient! public static final int APPLE_FUJI = 0; public static final int APPLE_PIPPIN = 1; public static final int APPLE_GRANNY_SMITH = 2; public static final int ORANGE_NAVEL = 0; public static final int ORANGE_TEMPLE = 1; public static final int ORANGE_BLOOD = 2;
メンバがコンパイル時にわかっている定数については, enumsを使うこと.
Item 35 : ordinal instanceよりfield instanceを使うこと
bit を使ってテキストスタイルを定義.
// Bit field enumeration constants - OBSOLETE!
public class Text {
public static final int STYLE_BOLD = 1 << 0; //1
public static final int STYLE_ITALIC = 1 << 1; // 2
public static final int STYLE_UNDERLINE = 1 << 2; // 4
public static final int STYLE_STRIKETHROUGH = 1 << 3; // 8
// Parameter is bitwise OR of zero or more STYLE_ constants
public void applyStyles(int styles) { ... }
}
OR演算は以下のように行う.
text.applyStyles(STYLE_BOLD | STYLE_ITALIC);
こういうケースはEnumSetを使うとよい.
// EnumSet - a modern replacement for bit fields
public class Text {
public enum Style { BOLD, ITALIC, UNDERLINE, STRIKETHROUGH }
// Any Set could be passed in, but EnumSet is clearly best
public void applyStyles(Set<Style> styles) { ... }
}
text.applyStyles(EnumSet.of(Style.BOLD, Style.ITALIC));
applyStyles()はSet<Style>となる.
enum型は集合の中で使われるので, bit fieldとして宣言する必要はない.
Item 37 : ordinal indexingの代わりにEnumMapを使うこと
ng
class Plant {
enum LifeCycle { ANNUAL, PERENNIAL, BIENNIAL }
final String name;
final LifeCycle lifeCycle;
Plant(String name, LifeCycle lifeCycle) {
this.name = name;
this.lifeCycle = lifeCycle;
}
@Override public String toString() {
return name;
}
}
// Using an EnumMap to associate data with an enum
Map<Plant.LifeCycle, Set<Plant>> plantsByLifeCycle = new EnumMap<>(Plant.LifeCycle.class);
for (Plant.LifeCycle lc : Plant.LifeCycle.values())
plantsByLifeCycle.put(lc, new HashSet<>());
for (Plant p : garden)
plantsByLifeCycle.get(p.lifeCycle).add(p);
System.out.println(plantsByLifeCycle);
ok
// Using an EnumMap to associate data with an enum
Map<Plant.LifeCycle, Set<Plant>> plantsByLifeCycle =
new EnumMap<>(Plant.LifeCycle.class);
for (Plant.LifeCycle lc : Plant.LifeCycle.values())
plantsByLifeCycle.put(lc, new HashSet<>());
for (Plant p : garden)
plantsByLifeCycle.get(p.lifeCycle).add(p);
System.out.println(plantsByLifeCycle);
こうすると, ArrayIndexOutOfBoundsExceptionを起こす心配をしなくてよくなる.
Item 38 : interfaceつきenumの拡張可能さを真似ること
// Emulated extensible enum using an interface
public interface Operation {
double apply(double x, double y);
}
public enum BasicOperation implements Operation {
PLUS("+") {
public double apply(double x, double y) { return x + y; }
},
MINUS("-") {
public double apply(double x, double y) { return x - y; }
},
TIMES("*") {
public double apply(double x, double y) { return x * y; }
},
DIVIDE("/") {
public double apply(double x, double y) { return x / y; }
};
private final String symbol;
BasicOperation(String symbol) {
this.symbol = symbol;
}
@Override public String toString() {
return symbol;
}
}
// Emulated extension enum
public enum ExtendedOperation implements Operation {
EXP("^") {
public double apply(double x, double y) {
return Math.pow(x, y);
}
},
REMAINDER("%") {
public double apply(double x, double y) {
return x % y;
}
};
private final String symbol ExtendedOperation(String symbol) {
this.symbol = symbol;
}
@Override public String toString() {
return symbol;
}
}
利点1: "base enum"が期待される任意の場所でextension enumの単一のインスタンスを渡すことができる 利点2: インスタンスの要素に加えてextension enum型全体を渡すことができる
public static void main(String[] args) {
double x = Double.parseDouble(args[0]);
double y = Double.parseDouble(args[1]);
test(ExtendedOperation.class, x, y);
}
private static <T extends Enum<T> & Operation> void test(
Class<T> opEnumType, double x, double y) {
for (Operation op : opEnumType.getEnumConstants())
System.out.printf("%f %s %f = %f%n", x, op, y, op.apply(x, y));
}
Item 39 : naming patternにアノテーションを好むこと
// Marker annotation type declaration
import java.lang.annotation.*;
/**
* Indicates that the annotated method is a test method.
* Use only on parameterless static methods.
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Test {
}
@Retention : Test annotationsが実行時に保持されるべきということを示す, これがないとtest toolからTest classのアノテーションが見えなくなる. @Target : Test annotationがmethod宣言時にのみ許されるということを示す. class宣言時やfield宣言時には許可されない.
// Program containing marker annotations
public class Sample {
@Test public static void m1() { } // Test should pass
public static void m2() { }
@Test public static void m3() { // Test should fail
throw new RuntimeException("Boom");
}
public static void m4() { }
@Test public void m5() { } // INVALID USE: nonstatic method
public static void m6() { }
@Test public static void m7() { // Test should fail
throw new RuntimeException("Crash");
}
public static void m8() { }
}
Item 40 : 一貫してOverrideアノテーションを使うこと
親クラスの宣言をoverrideするところには必ずアノテーションを使うこと.
使わないと, 例えば以下のようなケースで想定通りに動作しない.
// Can you spot the bug?
public class Bigram {
private final char first;
private final char second;
public Bigram(char first, char second) {
this.first = first;
this.second = second;
}
public boolean equals(Bigram b) {
return b.first == first && b.second == second;
}
public int hashCode() {
return 31 * first + second;
}
public static void main(String[] args) {
Set<Bigram> s = new HashSet<>();
for (int i = 0; i < 10; i++)
for (char ch = 'a'; ch <= 'z'; ch++)
s.add(new Bigram(ch, ch));
System.out.println(s.size());
}
}
このとき, s.size()は26ではなく260と出力される. overrideアノテーションがないとoverloadされるだけで親クラスのequals()が呼ばれるためである.
Item 41 : 型を定義するためにmarker interfaceを使うこと
marker interfaceはメソッドを含まず, それを実装したクラスにいくつかのプロパティを持つようにさせるinterfaceである.
例. Serializable interface
marker interface typeを使うと, 実行時に発生しうるエラーをコンパイル時に見つけることができる.
Item 42 : anonymous classよりlambdaを好むこと
ng
// Anonymous class instance as a function object - obsolete!
Collections.sort(words, new Comparator<String>() {
public int compare(String s1, String s2) {
return Integer.compare(s1.length(), s2.length());
}
});
ok
// Lambda expression as function object (replaces anonymous class)
Collections.sort(words,
(s1, s2) -> Integer.compare(s1.length(), s2.length()));
lambdaとparamsは実行時に型推論される.
もっと簡潔に以下のようにかける:
Collections.sort(words, comparingInt(String::length));
words.sort(comparingInt(String::length));
lambdaは名前とドキュメントがないので, 計算自体が何をやっているのか分かりやすくない, もしくは複数行を超えるのであれば, lambdaを使うべきではない.
Item 43 : lambdaよりmethod referenceを好むこと
lambdaよりmethod referenceのほうがより簡潔な関数オブジェクトである.
lambda
map.merge(key, 1, (count, incr) -> count + incr);
method reference
map.merge(key, 1, Integer::sum);
Item 44 : standard functional interfaceを利用すること
template method patternよりも, よりモダンな代用としてstatic factory/constructorに関数オブジェクトを与えられるようにすることが挙げられる.
ng
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return size() > 100;
}
ok
// Unnecessary functional interface; use a standard one instead.
@FunctionalInterface interface EldestEntryRemovalFunction<K,V>{
boolean remove(Map<K,V> map, Map.Entry<K,V> eldest);
}
java.util.Functionには43のinterfaceがある. Predicate, Supplier, Consumerあたりがメジャーどころ.
primitive functional interfaceのかわりにboxed primitivesつきのbasic functional interfaceを使うのは性能的によくない.
boxed primitiveをバルク演算のために使うのは性能がでない. (unboxingが多発するため)
※functional interface http://www.ne.jp/asahi/hishidama/home/tech/java/functionalinterface.html
Item 45 : 賢くstreamを使うこと
読むのが難しくなるようなstreamの使い方は良くない.
ng
// Overuse of streams - don't do this!
public class Anagrams {
public static void main(String[] args) throws IOException {
Path dictionary = Paths.get(args[0]);
int minGroupSize = Integer.parseInt(args[1]);
try (Stream<String> words = Files.lines(dictionary)) {
words.collect(
groupingBy(word -> word.chars().sorted()
.collect(StringBuilder::new,
(sb, c) -> sb.append((char) c),
StringBuilder::append).toString()))
.values().stream()
.filter(group -> group.size() >= minGroupSize)
.map(group -> group.size() + ": " + group)
.forEach(System.out::println);
}
}
}
// Tasteful use of streams enhances clarity and conciseness
public class Anagrams {
public static void main(String[] args) throws IOException {
Path dictionary = Paths.get(args[0]);
int minGroupSize = Integer.parseInt(args[1]);
try (Stream<String> words = Files.lines(dictionary)) {
words.collect(groupingBy(word -> alphabetize(word)))
.values().stream()
.filter(group -> group.size() >= minGroupSize)
.forEach(g -> System.out.println(g.size() + ": " + g));
}
}
// alphabetize method is the same as in original version
}
ng
// Iterative Cartesian product computation
private static List<Card> newDeck() {
List<Card> result = new ArrayList<>();
for (Suit suit : Suit.values())
for (Rank rank : Rank.values())
result.add(new Card(suit, rank));
return result;
}
ok
// Stream-based Cartesian product computation
private static List<Card> newDeck() {
return Stream.of(Suit.values())
.flatMap(suit ->
Stream.of(Rank.values())
.map(rank -> new Card(suit, rank)))
.collect(toList());
}
Item 46 : streamでside-effect-free(副作用のない) functionsを好むこと
ng
// Uses the streams API but not the paradigm--Don't do this!
Map<String, Long> freq = new HashMap<>();
try (Stream<String> words = new Scanner(file).tokens()) {
words.forEach(word -> {
freq.merge(word.toLowerCase(), 1L, Long::sum);
});
}
ok
// Proper use of streams to initialize a frequency table
Map<String, Long> freq;
try (Stream<String> words = new Scanner(file).tokens()) {
freq = words
.collect(groupingBy(String::toLowerCase, counting()));
}
Collectors (toList, toSet, toMap, groupingBy, and joining) の挙動を知っておくこと.
Item 47 : 返り値としてStreamよりCollectionを好むこと
streamクラスはIteratorのinterfaceしか持ってないため ユーザはstreamとしてだけでなく, iteratorを使って要素に参照したい場合もあるので, iteratorが実装されているCollectionを使うと良い.
Item 48 : stream parallelの際にはCautionを使うこと
Stream.iterateや中間表現limitが使われている場合, parallelで性能向上しない. スレッドセーフでない場合, 結果がおかしくなる. なので無差別にparallelしないこと. 使って良いのはArrayList, HashMap, HashSet, ConcurrentHashMap, arrays, int/long ranges.
Item 49 : validityのためにパラメータを確認すること
null checkはObjects.requireNonNullを使うこと.
assertを使うことで, 渡される変数の妥当性評価ができるので実施すべきである.
// Private helper function for a recursive sort
private static void sort(long a[], int offset, int length) {
assert a != null;
assert offset >= 0 && offset <= a.length;
assert length >= 0 && length <= a.length - offset;
... // Do the computation
}
method/constructorを書くときには, それらの引数などの制約を意識して妥当性評価すること.
Item 50 : 必要ならばdefencive copyをすること
性悪説に基づいた利用がされると想定してdefensiveに設計することが大切である.
以下の例では, setterを呼び出すことが出来てしまう
ng
// Broken "immutable" time period class
public final class Period {
private final Date start;
private final Date end;
/**
* @param start the beginning of the period
* @param end the end of the period; must not precede start
* @throws IllegalArgumentException if start is after end
* @throws NullPointerException if start or end is null
*/
public Period(Date start, Date end) {
if (start.compareTo(end) > 0)
throw new IllegalArgumentException(
start + " after " + end);
this.start = start;
this.end = end;
}
public Date start() {
return start;
}
public Date end() {
return end;
}
... // Remainder omitted
}
攻撃のコード
// Attack the internals of a Period instance Date start = new Date(); Date end = new Date(); Period p = new Period(start, end); end.setYear(78); // Modifies internals of p!
defensive copyを使うと防ぐことができる.
ok
// Repaired constructor - makes defensive copies of parameters
public Period(Date start, Date end) {
this.start = new Date(start.getTime());
this.end = new Date(end.getTime());
if (this.start.compareTo(this.end) > 0)
throw new IllegalArgumentException(
this.start + " after " + this.end);
}
攻撃を防ぐ観点で, 型をサブクラスにできるようなパラメータのコピーにdefensive copyを使うのはよくない.
Item 51 : method signatureの設計は気をつけること
methodの名前は気をつけて選ぶこと. 理解しやすく, 他と一貫した名前を選ぶこと.
あまりにも多くのmethodを作りすぎないこと. クラスを把握するのが難しくなるため.
長いパラメータのリストは避けること. パラメータの型が同じ場合, 引数の順序を間違えても動作してしまうため.
パラメータの型として, classよりもinterfaceを好むこと.
booleanより2要素のenum typeを好むこと. enumはコード可読性と書きやすさが上がる.
Item 52 : 賢くoverloadを使うこと
ng
// Broken! - What does this program print?
public class CollectionClassifier {
public static String classify(Set<?> s) {
return "Set";
}
public static String classify(List<?> lst) {
return "List";
}
public static String classify(Collection<?> c) {
return "Unknown Collection";
}
public static void main(String[] args) {
Collection<?>[] collections = {
new HashSet<String>(),
new ArrayList<BigInteger>(),
new HashMap<String, String>().values()
};
for (Collection<?> c : collections)
System.out.println(classify(c));
}
}
Javaのgenericsはcompile時にどのmethodを呼ぶか決まるため, 曖昧な場合はうまく呼ぶことができない.
ok
public static String classify(Collection<?> c) {
return c instanceof Set ? "Set" :
c instanceof List ? "List" : "Unknown Collection";
}
以下の原則を守ると良い. 同じパラメータ数を持つmethodをoverloadしないこと. 異なる名前をつけること.
Item 53 : varargsを賢く使うこと
// Simple use of varargs
static int sum(int... args) {
int sum = 0;
for (int arg : args)
sum += arg;
return sum;
}
ng
// The WRONG way to use varargs to pass one or more arguments!
static int min(int... args) {
if (args.length == 0)
throw new IllegalArgumentException("Too few arguments");
int min = args[0];
for (int i = 1; i < args.length; i++)
if (args[i] < min)
min = args[i];
return min;
}
ok
// The right way to use varargs to pass one or more arguments
static int min(int firstArg, int... remainingArgs) {
int min = firstArg;
for (int arg : remainingArgs)
if (arg < min)
min = arg;
return min;
}
引数を最低一つ保証する.
Item 54 : nullではなくempty collections/arraysを返り値とすること
ng
// Returns null to indicate an empty collection. Don't do this!
private final List<Cheese> cheesesInStock = ...;
/**
* @return a list containing all of the cheeses in the shop,
* or null if no cheeses are available for purchase.
*/
public List<Cheese> getCheeses() {
return cheesesInStock.isEmpty() ? null
: new ArrayList<>(cheesesInStock);
}
クライアント側もまたnull handlingが必要となってしまうので無駄である.
ok
//The right way to return a possibly empty collection
public List<Cheese> getCheeses() {
return new ArrayList<>(cheesesInStock);
}
immutable objectを返す場合, そのまま呼び出し先に渡されるので性能的にも効率が良い.
empty collectionsのallocationを防ぐために以下のような最適化もできる
// Optimization - avoids allocating empty collections
public List<Cheese> getCheeses() {
return cheesesInStock.isEmpty() ? Collections.emptyList()
: new ArrayList<>(cheesesInStock);
}
Item 55 : optionalは賢く返すこと
T でなく Optional<T> を返すことで, 特定の状況においてnullになりうるものを返すことができる.
// Returns maximum value in collection - throws
exception if empty
public static <E extends Comparable<E>> E max(Collection<E> c) {
if (c.isEmpty())
throw new IllegalArgumentException("Empty collection");
E result = null;
for (E e : c)
if (result == null || e.compareTo(result) > 0)
result = Objects.requireNonNull(e);
return result;
}
// Returns maximum value in collection as an Optional<E>
public static <E extends Comparable<E>>
Optional<E> max(Collection<E> c) {
if (c.isEmpty())
return Optional.empty();
E result = null;
for (E e : c)
if (result == null || e.compareTo(result) > 0)
result = Objects.requireNonNull(e);
return Optional.of(result);
}
// Returns max val in collection as Optional<E> - uses stream
public static <E extends Comparable<E>>
Optional<E> max(Collection<E> c) {
return c.stream().max(Comparator.naturalOrder());
}
Optionalを返すmethodで決してnullを返さないこと.
Collectuon, map, stream, array, optionalはoptionalでラップされるべきではない.
Optionalを返すのは, resultを返せない可能性がある時かつclientがそれに対して特別な処理をしなければならない時である.
boxed primitiveの optionalは返してはいけない.
Item 56 : 全ての公開されているAPI elementsのためにドキュメントを書くこと
そのためにはclass, interface, constructor, method, fieldの全てにドキュメントを書くこと. methodとそのclientの間の契約は簡潔に示すこと.
Item 57 : ローカル変数のスコープを最小化すること
その変数が利用されるところで宣言すると良い.
Item 58 : forループよりfor-eachループを好むこと
ng
// Not the best way to iterate over a collection!
for (Iterator<Element> i = c.iterator(); i.hasNext(); ) {
Element e = i.next();
... // Do something with e
}
// Not the best way to iterate over an array!
for (int i = 0; i < a.length; i++) {
... // Do something with a[i]
}
ok
// The preferred idiom for iterating over collections and arrays
for (Element e : elements) {
... // Do something with e
}
array参照の違反を防ぐことができる.
Item 59 : ライブラリを知って使うこと
ng
// Common but deeply flawed!
static Random rnd = new Random();
static int random(int n) {
return Math.abs(rnd.nextInt()) % n;
}
問題1. nが小さい2のべき乗の場合, 短い周期で乱数を繰り返す 問題2. nが2のべき乗でないとき, 出る乱数の割合に差が現れる
standard libraryを使うことで, 専門家の知識の恩恵に預かることができる.
全てのプログラマはjava.lang, java.util, and java.ioとそのsubpackagesに精通すべきである.
Item 60 : 正確な答えが必要なときfloatとdoubleを避けること
通貨の計算において, float/double型は部分的に不適切である. 例えば$1.03持っていて42セント使ったとする. いくら残っているか?という問いに対して, 残念ながら以下のコードだと0.6100000000000001を出力する.
System.out.println(1.03 - 0.42);
ng
public static void main(String[] args) {
final BigDecimal TEN_CENTS = new BigDecimal(".10");
int itemsBought = 0;
BigDecimal funds = new BigDecimal("1.00");
for (BigDecimal price = TEN_CENTS;
funds.compareTo(price) >= 0;
price = price.add(TEN_CENTS)) {
funds = funds.subtract(price);
itemsBought++;
}
System.out.println(itemsBought + " items bought.");
System.out.println("Money left over: $" + funds);
}
BigDecimal型を使うと良い. 丸めの制御もできる(例. 8 rounding mode). 性能の観点で考えるのであれば, 数が大きすぎなければint/long型を使うのも良い.
// Broken - uses floating point for monetary calculation!
public static void main(String[] args) {
double funds = 1.00;
int itemsBought = 0;
for (double price = 0.10; funds >= price; price += 0.10) {
funds -= price;
itemsBought++;
}
System.out.println(itemsBought + " items bought.");
System.out.println("Change: $" + funds);
}
Item 61 : boxed primitiveよりもprimitive typesを好むこと
これらの3つの違い 違い1. primitiveは値しか持ってないが, boxed primitiveは値を区別するための識別子を持っている. (同じ値で異なる識別子も可能) 違い2. primitive完全にfunctionalな値のみ持つが, boxed primitiveはnullのようなnonfunctionalな値を持つことができる. 違い3. primitiveはboxedより空間・時間計算量的に効率が良い.
boxed primitiveで上手くいかない例を示す
// Broken comparator - can you spot the flaw? Comparator<Integer> naturalOrder = (i, j) -> (i < j) ? -1 : (i == j ? 0 : 1);
boxed primitiveは==で比較しても値の評価はできない. equalsを使うこと.
二つを併用した場合, boxedはautounboxedされる. そのため, nullが入っているとヌルポを吐く.
boxedを使うときは, ケース1. 要素としてkey valueがcollectionのとき. collectionにはprimitiveを入れることができないので.
ケース2. パラメーター化された型やmethodで使うとき.
例えばThreadLocal<Integer>
ケース3. リフレクションのmethod呼び出しをするとき.
これらに当てはまらず, どちらを使うか選択できる場合は極力primitiveを使うこと.
Item 62 : 他の型が適する場合はstringを避けること
理由1. 他の型よりも機能が充実していないため. 例えばnumericならint, float, BigIntegerなどの数値型を使うべき.
理由2. enumのほうが優れているため.
理由3.型をaggregateするのに向いていないため.
// Inappropriate use of string as aggregate type String compoundKey = className + "#" + i.next();
Stringをparseしてerror handlingして, ...と労力が高い. この場合はclassを作るのが良い.
// Broken - inappropriate use of string as capability!
public class ThreadLocal {
private ThreadLocal() { } // Noninstantiable
// Sets the current thread's value for the named variable.
public static void set(String key, Object value);
// Returns the current thread's value for the named variable.
public static Object get(String key);
}
スレッド間で意図しないString keyの共有がなされる危険がある.
Item 63 : string concatenationのパフォーマンスに気を付けること
Stringのconcatenation(+)は結合するnの二乗の時間がかかる. immutableなので, それぞれのstringはcopyされる.
// Inappropriate use of string concatenation - Performs poorly!
public String statement() {
String result = "";
for (int i = 0; i < numItems(); i++)
result += lineForItem(i); // String concatenation
return result;
}
こういうケースはStringBuilderを使うとよい.
public String statement() {
StringBuilder b = new StringBuilder(numItems() * LINE_WIDTH);
for (int i = 0; i < numItems(); i++)
b.append(lineForItem(i));
return b.toString();
}
2, 3個のconcatenationは良いが, それ以上はBuilderを使うこと.
Item 64 : interfaceを使ってobjectに参照すること
ng
// Bad - uses class as type! LinkedHashSet<Son> sonSet = new LinkedHashSet<>();
ok
Set<Son> sonSet = new HashSet<>();
Item 65 : reflectionよりinterfaceを好むこと
reflection 利点. privateなconstructor, field, methodを参照できる 欠点1. コンパイル時の型チェックが意味をなさなくなる 欠点2. reflectionが必要なコードは不器用で冗長になる 欠点3. 性能がでない
reflectionを使う場合はinstance化できるobjectのみに限定し, 参照はコンパイル時に既に分かっているinterfaceかsuperclassを利用することが良い.
Item 66 : native methodを賢く使うこと
JNIを使ってC/C++のようなnative programmingができる.
性能向上のために使うのは殆ど考えられない. low levelなリソースを使う, native libraryを使うためにnative methodをどうしても使わなければならない場合は, 最低限にしてテストを徹底すること.
Item 67 : 賢く最適化すること
名言3つ
速いより良いコードを書こう. 良いコードとはカプセル化による情報隠蔽, 各クラス間の依存が極力ないようにする等.
性能に限界をもうけるような設計は避けよう.
Item 68 : 一般的に受け入れられる名前の慣習によりそうこと
CamelCaseでの統一や定数・enmuは大文字にする等.
Item 69 : 例外条件があるときのみexceptionを使うこと
不要な例外ハンドリングは極力避ける.
ng
// Horrible abuse of exceptions. Don't ever do this!
try {
int i = 0;
while(true)
range[i++].climb();
} catch (ArrayIndexOutOfBoundsException e) {
}
これはfor eachで例外ハンドリングを消せる.
ok
for (Mountain m : range)
m.climb();
Item 70 : 回復可能な条件や実行時エラーのためにchecked conditionを使うこと
もし疑問や違和感があるなら, unchecked exceptionを投げてもよい. checked exceptionとruntime exceptionのいずれでもないものは定義してはいけない.
Item 71 : checked exceptionの不必要な利用は避けること
不必要に使うと, APIを利用する側が使いづらくなってしまう. もし利用者側にexceptionのhandlingを要求したい場合は, まずoptionalの利用を検討する.
Item 72 : standard exceptionの利用を好むこと
IllegalArgumentException IllegalStateException Nullpo ConcurrentModificationException UnsupportedOperationException
IllegalStateExceptionは引数がたったひとつも適切でない場合
Item 73 : abstractionには適切にexceptionを投げること
高いレイヤでは低レイヤのexceptionを捕まえ, 抽象的でない具体的なexceptionを投げること. 利用者にとって参考情報となるため.
Item 74 : 個々のmethodによって投げられるexceptionはドキュメント化すること
unchecked exceptionではthrowsを使わないこと
Javadocの@throwsをmethodにつけること
clasS内に多数のthrowしうるmethodがある場合, classにまとめてドキュメント化してもよい.
Item 75 : detail messageにfailure-capture informationを含むこと
failureを捕まえるため, exceptionのdetail messageは関係のある全パラメータの値とfieldを含むべき.
Item 76 : failure atomicityとなるよう努力すること
一般的に, methodを呼び出して失敗した場合には, 呼び出し前の状態に戻すべきである.
Item 77 : exceptionを無視しないこと
ng
// Empty catch block ignores exception - Highly suspect!
try {
...
} catch (SomeException e) {
}
無視する場合は以下のようにコメントとignoredという名前を使うこと
ok
Future<Integer> f = exec.submit(planarMap::chromaticNumber);
int numColors = 4; // Default; guaranteed sufficient for any map
try {
numColors = f.get(1L, TimeUnit.SECONDS);
} catch (TimeoutException | ExecutionException ignored) {
// Use default: minimal coloring is desirable, not required
}
Item 78 : 共有されたmutable dataを参照できるようにsyncronizeすること
syncronizationはread/write命令がsyncronizeされるまで, 動作を保証しない.
ng
// Broken! - How long would you expect this program to run?
public class StopThread {
private static boolean stopRequested;
public static void main(String[] args)
throws InterruptedException {
Thread backgroundThread = new Thread(() -> {
int i = 0;
while (!stopRequested)
i++;
});
backgroundThread.start();
TimeUnit.SECONDS.sleep(1);
stopRequested = true;
}
}
ok
// Properly synchronized cooperative thread termination
public class StopThread {
private static boolean stopRequested;
private static synchronized void requestStop() {
stopRequested = true;
}
private static synchronized boolean stopRequested() {
return stopRequested;
}
public static void main(String[] args)
throws InterruptedException {
Thread backgroundThread = new Thread(() -> {
int i = 0;
while (!stopRequested())
i++;
});
backgroundThread.start();
TimeUnit.SECONDS.sleep(1);
requestStop();
}
}
Item 79 : 過剰なsyncronizationは避けること
スレッド利用時のliveness, 安全の観点から, syncronization methodの途中で, clientにcontrollを渡さないこと.
mutable classは極力自クラスで簡潔するように作ること.
Item 80 : threadsよりexecutors, tasks, streamsを好むこと
任意かつ全てのtaskのcollectionが終わるのを待つことができる, というようにthreadsよりも多機能であるため.
Item 81 : wait/notifyよりもconcurrency utilitiesを好むこと
wait/notifyを正しく使うことの難しさを考えると, より高いレベルのconcurrency utilitiesを使うべき.
Collections.synchronizedMapよりもConcurrentHashMapを使うこと
Item 82 : thread safetyのためドキュメント化すること
methodのdocumentationの中にあるsyncronized modifierを探すことで, そのmethodがthread-safeであるかどうかを知るというのは間違っている. method宣言のsynchronized modifierは実装の詳細部分に存在すべき.
安全にconcurrentを利用するため, classはどのレベルのthread safetyが担保されているかドキュメント化しなければならない. レベルは以下のように分類される:
- immutable
- Unconditionaly thread-safe
- Conditionaly thread-safe
- Not thread-safe
- Thread-hostile
Item 83 : lazy initializationを賢く使うこと
多くの状況において, normal initializationがlazy initializationより好まれる.
normal initialization
// Normal initialization of an instance field private final FieldType field = computeFieldValue();
lazy initialization
// Lazy initialization of instance field - synchronized accessor
private FieldType field;
private synchronized FieldType getField() {
if (field == null)
field = computeFieldValue();
return field;
}
もしstatic fieldにおいて性能のためにlazy initializationを使う必要があるならば, lazy initialization holder class idiomを使うこと.
// Lazy initialization holder class idiom for static fields
private static class FieldHolder {
static final FieldType field = computeFieldValue();
}
private static FieldType getField() { return FieldHolder.field; }
instance fieldにおいて性能のためにlazy initializationを使う必要があるならば, double-check idiomを使うこと.
// Double-check idiom for lazy initialization of instance fields
private volatile FieldType field;
private FieldType getField() {
FieldType result = field;
if (result == null) { // First check (no locking)
synchronized(this) {
if (field == null) // Second check (with locking)
field = result = computeFieldValue();
}
}
return result;
}
Item 84 : thread schedulerに依存しないこと
thread schedulerに頼ったプログラムは移植性が低い.
最も良い方法はrunnable threadsの平均数をprocessorsの数より多くしないことである.
taskは短くすること, ただし短くしすぎるとthread生成やdispatching overheadが性能に影響を与える.
Thread.yieldに依存しないようにすること.
Item 85 : Java serializationよりalternativeを好むこと
serializationの問題は, attack surfaceが大きすぎて守ることができない点である.
serializationは危険で, 避けるべきである.
アーキテクチャを1から設計する場合, cross-platformな構造データ表現方法を使うこと(JSONやprotobuf).
セキュリティ観点から信頼できないデータはdeserializeしないこと.
Item 86 : 気をつけてSerializableを実装すること
Serializableの実装で最もコストがかかるのは, classの実装を変更する柔軟性が減ることである. classがSerializableを実装すると, byte-stream encoding(= serialized form)はAPIの一部となる. 一旦classを幅広いclientに提供すると, そのserialized formを永遠にsupportすることを望まれる. もしdefault serialized formを受け入れると, classのprivate fieldやpackage-private instance fieldsはAPIの一部となり, 情報を隠蔽するためにfieldへの参照を最小化する(Item 15)というbest practiceが失われる.
2番目は, バグとセキュリティホールの尤度が高くなること.
3番目は, 新しいバージョンのclassをリリースする際のテストの重荷が増えること.
基本的には実装すべきではない.
Item 87 : custom serialized formの利用を考えること
serializableであるべきclassを決めたとき, formについて熟考すること.
objectの論理的な状態の説明に理がかなっているときにのみdefault serialized formを使うこと. そうでなければ custom serialized formを使うこと.
将来のバージョンで, 既に出されているmethodが削除できないのと同様に, serialized formからもfieldを消すことはできないので, 気をつけて設計すること.
Item 88 : 安全にreadObject methodを書くこと
readObjedct methodを書くときは常に, 何のbyte streamが与えられているかに関係なく, 有効なinstanceを生成しなければならないようなpublic constructorを書いているという気持ちを持つこと.
以下のガイドラインに従うこと:
- privateのままにする必要があるobject reference fieldを持つclassの場合, そのようなfieldの各objectを防御的にコピーする.
- InvalidObjectExceptionを投げるか確認する.
- もしvalidationが必要であればObjectInputValidation interfaceを使うこと.
- classの中でoverridableなmethodを呼び出さないこと.
Item 89 : instance controlのためreadResolveよりenumを好むこと
instance controllを不変にするため, できるだけenumを使うこと. もしこれgあ不可能でclassがserializableでinstance-controlledにする必要がある場合, readResolve methodを提供すべき.
Item 90 : serialized instancよりserialization proxiesを考えること
readObject/writeObject methodを書く時には, serialization proxy patternを検討してみること. このパターンは自明でない不変で, ロバストなserialize objectを書くのに最も簡単な方法となりうる.